Text-Driven Image Manipulation/Generation with CLIP

Chinese version is here : 用CLIP達成文字操弄/生成影像
It’s December 2021, quite a few algorithms are booming this year, they can manipulate/generate images with text input.
These algorithms and results touch my heart, they can
Just use (1 or 0 images, 1 text) to complete the above image generation/manipulation task
In Text2Mesh, Input is (a 3D Mesh,Text)
Note of CLIP Methods List:
Column : Pretrained Bone Model
Ghiasi26 is an arbitrary style transfer model released by magenta .
The [Per Text Per Model] version in CLIPstyler needs a pre-trained VGG-19 AutoEncoderDifference between [Optimization Based]/[Per Text Per Model]/[Arbitrary Text Per Model]:
Optimization Based:
It needs to train something for generating a new picture. It is not a real time alogrithm.Per Text Per Model:
A model specially trained for one text, which can inference in real time after training that modelArbitrary Text Per Model:
Only StyleCLIP in this list, their methods can serve any text and given face data in real time
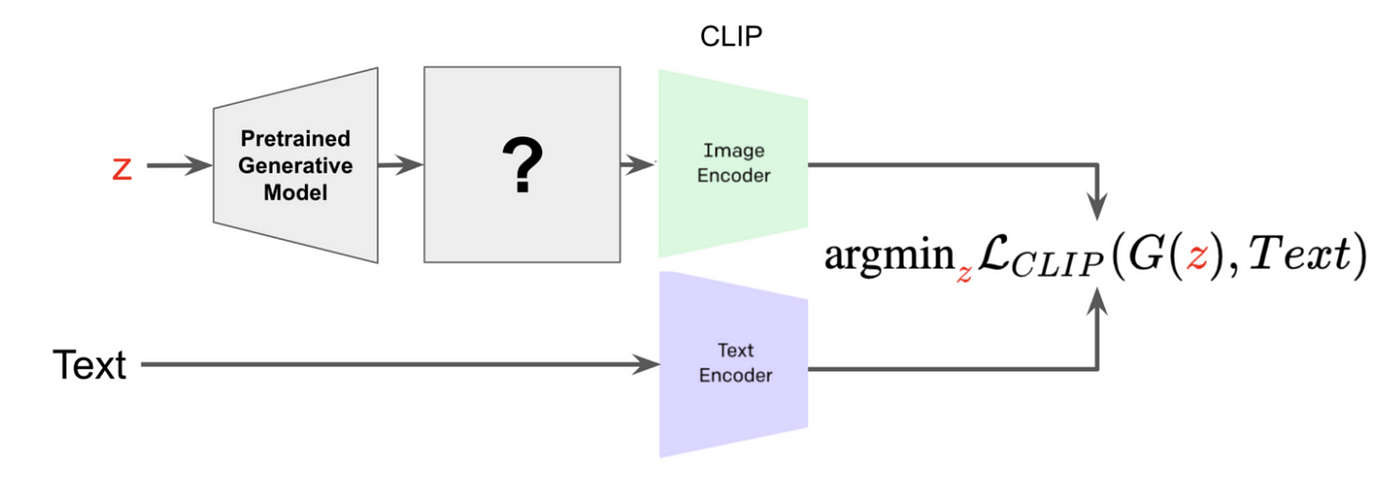
To generate these results, you need to use the model CLIP, which was released by OpenAI in early 2021
CLIP can measure the similarity between a (text, image) pair. Using this similarity as one of the loss functions is the core item to make these algorithms work!
This medium aims to extract the generalized parts of each algorithm I have read.
If you want to know the detail in CLIP, you can watch the following youtube video
We can measure the similarity between (image, text) with OpenAI’s CLIP
To use a pre-trained CLIP, only three steps here
- Send images and text into CLIP’s image encoder and text encoder respectively
- Get image embedding, text embedding from the previous step
- Calculate the cosine similarity of them
That's all!
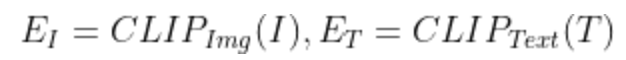
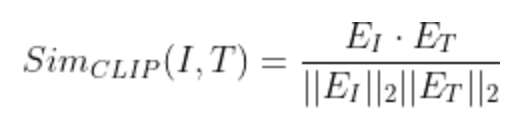
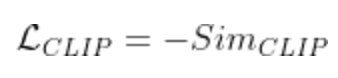
The goal of the general CLIP image generation algorithm are as follows:
- Give a text prompt
- With an optimization engine, find the image which minimizes the CLIP loss function
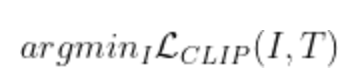

Of course, it’s not that simple
If you do gradient descent directly on the pixels of the image, you will get very poor results
After a year, some good papers/GitHub repos are released
After I read these methods, I extracted the more representative, general, and practical parts to the following points:
- Use Pre-trained Models from Other Image Generation Tasks
- Parametric Lines and Color Blocks; Shared Feature Transfer
- Collecting Measurements from Multiple Master Models
- Relative Position in CLIP Space
- Data Augmentation
- My Experiment in Style Transfer Model
This medium extract the general parts from various papers and reorganizes them.
If you want to know the details of each method, please read the original paper and the code by yourself.
1. Use Pre-trained Models from Other Image Generation Tasks
As mentioned earlier, it is not a good idea to directly optimize on the pixels of the image.
Many pre-trained image generation models have the ability to generate good images from their latent space easily. It would be a good choice to get the result stems from these existing models.
1.a. Optimize in the Latent Space of an Existed Model to Get Same Domain’s Result

StyleCLIP uses StyleGAN2’s pre-trained model.
StyleGAN2’s latent space has the ability to generate various kinds of faces.
The easiest way mentioned in the previous section is to optimize the image pixel directly.
In StyleCLIP, it is changed to optimize in the StyleGAN2 latent space.
If you want to modify the real face photo with StyleCLIP, you need to find which latent produces the image that is most similar to the real photo.
1.b. Modify the Weights of the Pre-Training Model to Achieve the Generation in Different Domain


StyleCLIP is surfing on StyleGAN2’s latent space, thus their algorithm does not have the ability to generate non-distribution results, such as werewolves, zombies, and vampires.
To make domain changing is possible, StyleGAN-NADA tries to adjust the weight of a few layers in StyleGAN2.
If all the weights are allowed to change, their experimental results are very poor
In the “Fast style transfer” version of CLIPstyler, they use a pre-trained VGG AutoEncoder as the initial weight, in which only the weight of the entire decoder is trainable.


2. Parametric Lines and Color Blocks; Shared Feature Transfer
Direct optimization of the pixel value will lead to a bad result. Using a pre-trained generator was mentioned in the previous section.
If you are eager to train something from scratch, you can try the following practices.
2.a. Parametric Lines and Color Blocks
When humans are observing and creating images, the observations are usually not based on each pixel but based on the characteristics of certain larger blocks, such as a stroke of a brush or a block of color.

In CLIPDraw, they use CLIP to guide a large number of curves to draw an image

Each curve is a Bézier curve, and each curve is parameterized with many control points
The parameters of each control point are parameterized with these attributes
- Location
- Color, transparency
- Thickness
Previous research make it is possiable to connect the gradient of the pixel to the parameters of the control points.
With this engine, we can simply apply the optimizer of the modern deep learning library(PyTorch) directly.Li, Tzu-Mao, et al. “Differentiable vector graphics rasterization for editing and learning.” ACM Transactions on Graphics (TOG) 39.6 (2020): 1–15.
2.b. Shared Feature Transfer
Other than using a hardcore engine in the previous section, you can also try shared feature transform methods below
In aphantasia, they use the following two traditional features to construct their image:
- Discrete Wavelet Transform
- Fast Fourier transform
Any feature in those feature spaces has collected plenty of pixel values’ information.
Other than using DWT & DCT, CLIPstyler train a convolutional neural network for a given input (image, text) pair for getting a style transfer result.
The convolutional operation has a property that each patch shared the same mathematical operation.
Highlight here, most of the research eager to find a neural network can serve any input
Take CycleGAN as an example, they hope to find a model have ability to transfer any zebra image into a horse, or vice versa
In CLIPstyler, this neural network only serve a single pair (one input image, one text), and it will be discarded after the service is completed.

In a more complicated case, The red box of above image, Text2Mesh is eager to add text semantic to a given 3d object. In their approach, they try to create a map function style field network, to map every vertex from (x, y, z) to (r, g, b, d) with a trainable neural network
Where d is displacement, the relative distance from original input vertex along the normal direction
3. Collecting Measurements from Multiple Master Models
When buying games in Steam, the bundle is a better strategy.
In the same way, is it greedy enough to just use the loss function of CLIP?
Mixing multiple models all together will get a miraculous effect!
3.a. Master Models in Various Domains
Many researchers have open-sourced their models, we can combine them to the current tasks in a beautiful way.


In style transfer, it usually needs two losses: content loss, and style loss. Minimizing the mixture of these two terms will make us get a stylized image.
In CLIPstyler, they use content loss computed with VGG to preserve the whole structure of the content image, for style term, they use CLIP loss for getting style information.
In StyleCLIP, the desired new image should be the same person, but other features (like hairstyle, emotion, age, lipsticks) are transformed. For this reason, StyleCLIP computes identity loss with the existing model: ArcFace. This model can measure the similarity of different face photos.
If you want to change the character, don’t use identity loss.
For example , if you are eager to change any face to Trump, then don’t use identity loss.
3.b. Multiple CLIP
OpenAI has many experiments when training CLIP. These different architecture CLIP models have been released.
In Pixray, they use multiple CLIP models to calculate the loss function at the same time.
The author of Pixray is Tom White, he is a well-known AI artist
His previous work Perception Engines have same idea.
The difference between them:
Pixray uses multiple CLIP at the same time to calculate the similarity to the text
Perception Engines shared use four model : inceptionv3, resnet50, vgg16 and vgg19 trained on ImageNet to calculate the response for a given ImageNet class.
4. Relative position in CLIP space
Daytime is hotter than night, restaurants are more expensive than snacks, winter is colder than summer, Madagascar is located in southeastern Africa.
We can bring out the relative relationship of two objects at once through comparison
While guiding, the relative relationship is a more effective concept.
The original mission might be: Arrive to New York
The better description is as follows:
- From San Francisco to New York
(should go east) - From Mexico to New York
(should go northeast)
If you don’t know where you are, you won’t know the direction.
The following two methods are needed to manually register the current semantic in CLIP, and then use the relative position to guide the algorithm.
4.a. StyleCLIP Global Direction
Global Direction, the third algorithm in StyleCLIP has the ability to convert any feature from source to target in real-time as in the video above.
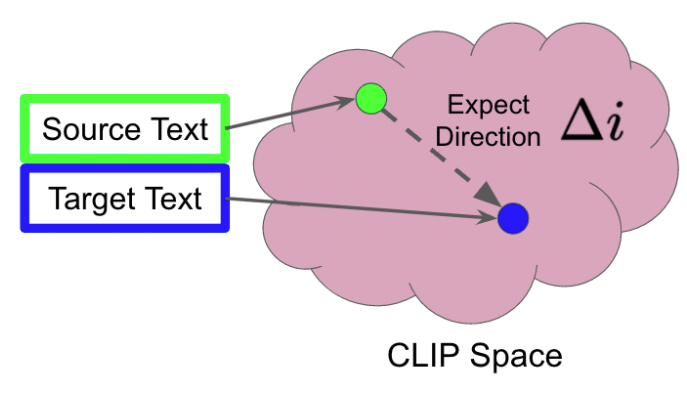
When doing this algorithm, there are three inputs (original image, description for original image, description for target).
Then calculate the relative position (Δi) of (description for the original image, target description) in the CLIP space.
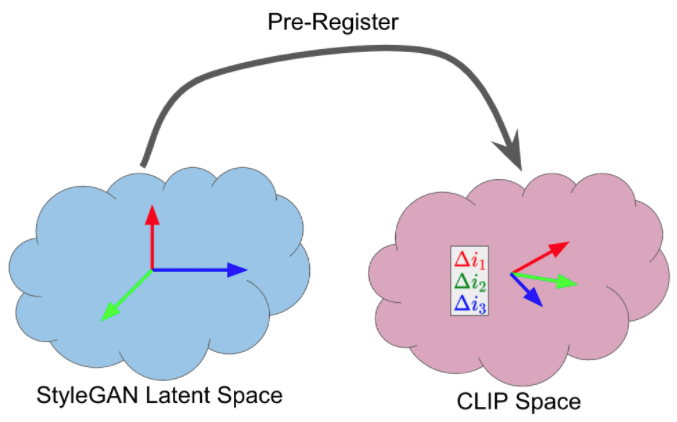
StyleCLIP is eager to find which direction in StyleGAN latent space leads to Δi in CLIP space.
To make the algorithm in real-time, their approach is to pre-register the response direction in CLIP space if we modify each channel in StyleGAN space.
Finally, the direction in StyleGAN latent space is obtained from the following formula, in which increasing the threshold β under their algorithm can prevent response to related features (such as the feature with white hair is usually the feature of the elderly, increase the threshold β can avoid that)
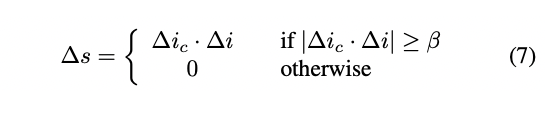

4.b. Directional Loss in StyleGAN-NADA
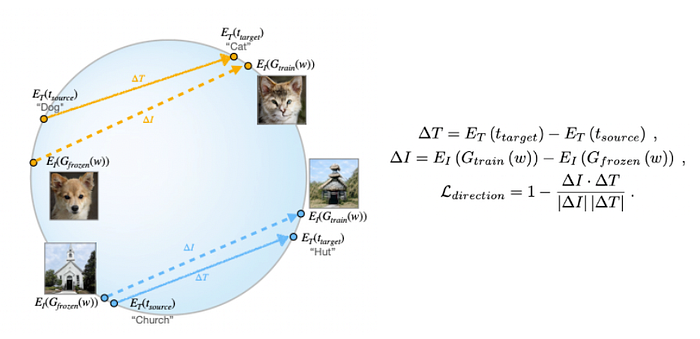
In the previous section, StyleCLIP uses the pre-registered (StyleGAN, CLIP) spatial relationship between the two latent spaces, and uses post-processing to get which direction to go in StyleGAN.
In StyleGAN-NADA, the relative position was written as a loss function explicitly, and this loss function is used to update the weight of the neural network.
Their target is to maximize the cosine similarity of the two vectors described below:
- The (source text→ target text) direction in CLIP text space (ΔT)
- The (original StyleGAN output → trained StyleGAN output) direction in CLIP image space (ΔI)
5. Data Augmentation
Generally, data augmentation is a common technique when training an image model. Common techniques such as zooming in, zooming out, rotating, shift, crop, adding noise, etc.
The reason is that, even though we disturb the data slightly, it is still invariant to the original attributes.
5.a. Straightforward Augmentation
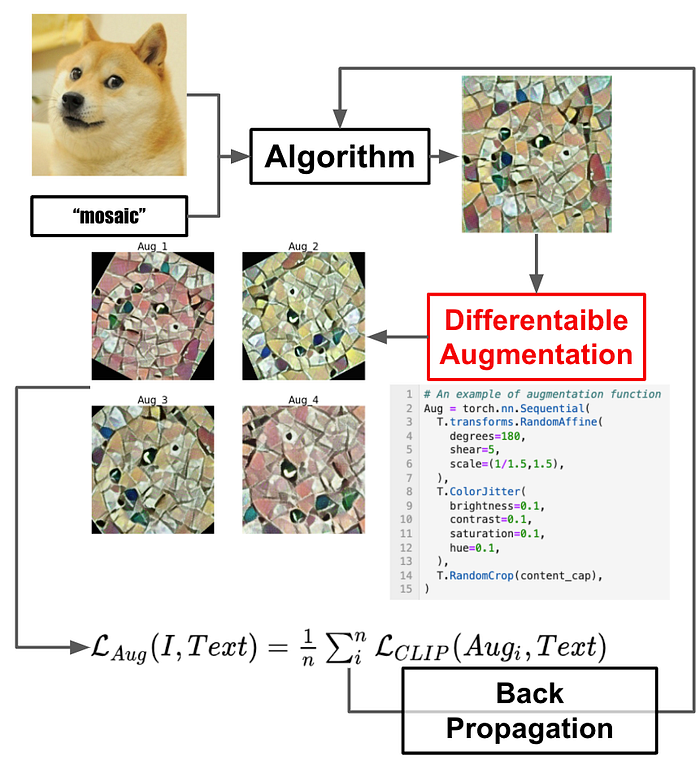
BigSleep, the first image generation project with CLIP, has already started using data augmentation
Many of the subsequent CLIP image manipulation/generation algorithms also use data augmentation too. We expect that the disturbed result image should be measured very similarly to the input text with CLIP.
The simplest data augmentation is shown in the figure above. After we apply differentiable augmentation to the intermediate output of the algorithm, multiple new images are obtained. We can obtain the augmented loss function by gathering these new pictures’ CLIP loss function.


The red box of above image, Text2Mesh project a 3d object to multiple 2d images from multiple views, then apply augmentation to these images.
5.b. Is it Necessary to Augmented the Generated Image?

Although the CLIP model is great, it is too easy to be confused by adversarial attack.
- Adv. Example on CLIP in FuseDream
Uses the attack algorithm FGSM to perturb the pixels. The similarity under CLIP will be significantly improved(0.195➔0.259), but the human perception and the similarity of the augmented version are almost not significantly improved. - The Adv. Example on AugCLIP in FuseDream
Applies the same algorithm to the augmented loss function. There is almost no significant improvement in both similarity measures.
FGSM is an attacking algorithm. It adds a very small disturb values to the photo, and it is difficult to observe the difference with the original photo on the naked eye.
If you want to understand FGSM, it is recommended to read this notebook: Adversarial example using FGSM
The results of CLIPDraw and FuseDream are very poor without data augmentation.
However, SytleCLIP can get good results without using data augmentation.
My comment is that, if you cannot get a good result before augmentation, then you can try it.


5.c. Augment in Latent Space

The simple image augmentation methods are introduced in the previous section.
The FuseDream’s algorithm tries to augment at latent space
Their first algorithm is described below
- Sample N latents from BigGAN latent space
- Generate images from these latents
- Compute CLIP similarity with the given text
- Get first K highest score candidates (K << N)
- Optimize with the weighted mixture of these latent space candidates
6. My Experiment in Style Transfer Model


The arbitrary style transfer model proposed by the google team in 2017 has the ability to stylize any content image in real-time.
They have two networks
- Style prediction network P will encode the style image to → S
- Transfer network T will use → S and content image c to get a stylized image.

github : https://github.com/mistake0316/CLIPStyleTransfer
replicate : https://replicate.com/mistake0316/style-transfer-clip
In my experiment, I want to minimize the clip loss by optimizing the →S without any style image
There are three sets of experiments
- w/o data augmentation
- w/ data augmentation
- a batch of images + data augmentation
This algorithm takes about 1 minute to process a 384 x 384 image using a GTX 1080 Ti
The result is as follows
w/o data augmentation






w/ data augmentation






Tow honey semantic in honey!
a batch of images + data augmentation

As the gif shown below, in a batch of images + data augmentation approach, I found that the structure of content image will disappear if I do optimization without content loss.


a batch of images + data augmentation without content loss






a batch of images + data augmentation with content loss






Summary For My Method
After observing my results, the version w/ augmentation is more preferred for me, and it is relatively easier to control
I also try to train a model map CLIP image encode to Style Predictor encode, then feed text to this model. But it got bad results.
Since my bone model is serving for style transfer, it is impossible to do other tasks, such as face feature transfer in StyleCLIP.
The End of this Medium



Images by author, powered by pixray with text prompts : (left) japan bookstore | (mid) city in anime with sunshine | (right) 3d battleshipThere are more amazing images in pixray’s discord
CLIP was released in January 2021, it can measure the similarity between cross-domain information (images, text)
After a year, there are already many high-quality text-driven image manipulation/generation resources.
This research branch is still in the rapid growth stage. I think it is a good time to enter this topic.
The methods described in this article are a set of individual modules, you can easily insert any of them into an existing algorithm or combine them to create a new algorithm.
If you are interesting to the methods above,
This is a long medium, and it is my first English medium, maybe some errors are here
If you have any feedback or additional resources, please let me know :)
