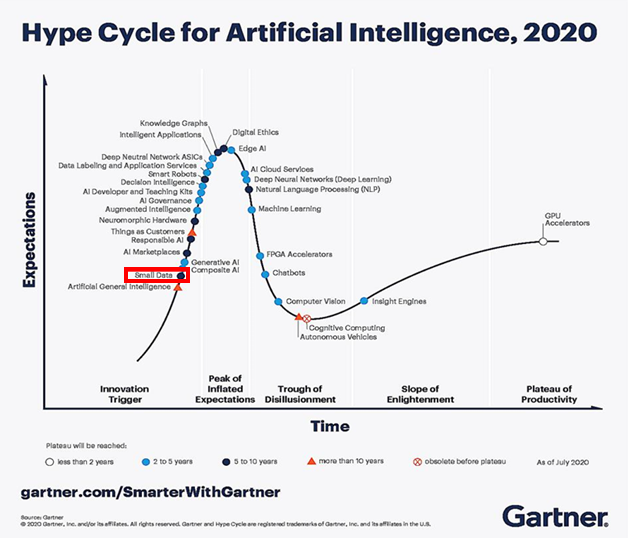
用CLIP達成文字操弄/生成影像

English Version is Here : Text-Driven Image Manipulation/Generation with CLIP
現在是2021年12月,今年有蠻多演算法能夠基於CLIP用文字去操弄/生成影像
這些演算法搔到了我的癢處,他們
僅僅只需要用(1或0張影像, 1段文字)即可完成上圖任務
要生成這些結果需要用到OpenAI在2021年初釋出的模型:CLIP
CLIP能夠衡量(文字, 影像)的相近程度,而要如何將這相近程度當做損失函數之一,則就是這些演算法畫龍點睛之處
這篇medium旨在摘要各個演算法中較泛用的部分
若還不知道CLIP,可以去看我的簡單介紹
註 Pretrained Bone Model :
Ghiasi26 為magenta釋出的任意風格轉換模型
CLIPstyler 在 Per Text Per Model 版本中使用了 預訓練的 VGG-19的 AutoEncoder註 Optimization Based/Per Text Per Model/Arbitrary Text Per Model 區別 :
Optimization Based :
每次生成一張新的圖片都需要重新訓練一次,不能實時輸出Per Text Per Model :
特別針對一個文字訓練一個的模型,訓練完後能夠實時輸出Arbitrary Text Per Model :
列表中僅有StyleCLIP,他們的方法可以服務任何文字,並且能實時輸出
CLIP能量測影像與文字的相關程度
使用預訓練的CLIP只要三個步驟
- 將影像、文字,分別送入CLIP的影像模型、文字模型
- 得到影像向量、文字向量
- 計算兩個向量的餘弦相似度
在一般的CLIP影像生成任務的目標如下:
- 給定文本
- 透過優化引擎,找到使得損失函數最低的一張影像

當然,事情沒有這麽簡單
如果是直接對影像的像素做梯度下降,會得出非常差的結果
經過了一年的催效後有一些不錯的方法產生
我從這些方法中濃縮了較具代表性、通用、實用的部分至以下幾點:
- 使用其他影像生成任務的預訓練模型
- 參數化的線條、色塊;共同的特徵轉換
- 集合眾大師模型的量測
- CLIP空間中的相對位置
- 資料增量
- 個人在風格轉換模型中的實驗結果
這篇medium把各個論文打散後重組,並不是依附於某篇論文下去講
若想看知道各方法的細節請自行觀看原論文、程式碼
1. 使用其他影像生成任務的預訓練模型
前面提到直接對影像的像素動手腳不是一個好選擇
許多預訓練的影像生成的模型已經能夠生成很好的影像,若改成對這種已經存在的模型動手腳會是個不錯的選擇
1.a. 操弄模型的隱藏的輸入(Latent)來達成同樣領域的生成任務

StyleCLIP使用了StyleGAN2的預訓練模型
StyleGAN2的各種Latent有能力生成各式各樣的人臉
上一小節提到的最簡易的版本是直接對影像的像素作優化,StyleCLIP中將其改為對StyleGAN2的Latent做優化,讓現在有能力透過使用CLIP來達成用文字導引Latent的走向

而若要修改真實的人臉照片,需要找到哪個 latent產生出來的影像與真實照片最為相近
1.b. 更新預訓練模型的權重,來達成不同領域的生成


StyleCLIP僅僅是依附於StyleGAN2本身的可能性
在預訓練的StyleGAN2模型不可能生成其他領域的人臉
如不可能生成狼人、殭屍、吸血鬼這種不同領域的資料
要達成領域的轉換,StyleGAN-NADA試著更動某幾層的權重
如果全部的權重都允許更動實驗結果很差
而在CLIPstyler中的Fast style transfer版本
他們拿預訓練的VGG AutoEncoder來作為初始權重,其中只對整個解碼器部分做權重更新


2. 參數化的線條、色塊;共同的特徵轉換
直接對像素值做優化會出現不好的狀況
上一小節介紹了使用已經預訓練的生成器的做法
如果想要從頭開始訓練,可以嘗試以下做法
2.a. 參數化的線條、色塊
人在觀察、創作影像時,通常不是依據每個像素點,而是根據某些較大塊的特徵去做觀察,如一筆筆線條、一塊塊色塊

在CLIPDraw中,他們用CLIP來指引一大批線條來畫圖

其中每個線條都是Bézier曲線,每個曲線都用很多個控制點的參數來描述
其中每個控制點的參數有
- 位置
- 顏色、透明度
- 粗細度
前人的研究能將像素點的梯度與控制點的參數串連起來
有了這個引擎後就可以簡單的直接套用開源深度學習套件(PyTorch)的優化器了Li, Tzu-Mao, et al. “Differentiable vector graphics rasterization for editing and learning.” ACM Transactions on Graphics (TOG) 39.6 (2020): 1–15.
github : https://github.com/BachiLi/diffvg
2.b. 共同的特徵轉換
除了局部色塊的設定特徵,也能嘗試使用一些牽一髮而動全身的特徵轉換來做影像生成
在 aphantasia 中就有兩種轉換的特徵空間來做影像生成,操弄下述特徵空間的特徵時會同時連動非常多的像素
- 離散小波轉換(Discrete Wavelet Tranform)
- 傅立葉轉換(Fast Fourier transform)
除了使用傳統方法的特徵空間,訓練一個神經網路來做影像轉換也是選項之一
在CLIPstyler中的其中一個版本就 專門為了一張輸入影像 設計一個卷積神經網路來做風格轉換
卷積層特性就是,對不同的區塊,他們都是做同樣的特徵轉換。
再特別強調一下,大部分的研究是希望一個神經網路能服務任何輸入
如 CycleGAN 希望找到一個模型能將 任何 斑馬影像轉換為馬,或反過來
而此處這個神經網路的參數只服務單一配對(一張輸入影像,一段文本),服務完就丟棄

複雜一點的,在Text2Mesh中,他們想要為原先的無色的三維網格賦予給予文本的特性。在他們的作法中,要學一個神經網路,讓每個頂點從三維空間(x, y, z)映射至(r, g, b, d)
其中 d 位移長,方向是原模型頂點的垂直(normal)方向
3. 集合眾大師模型的量測
買遊戲時都是買同捆包會比較優惠
同理,只用CLIP的損失函數是不是不夠貪心?
把多個模型全部攪在一起使用會有奇效!
3.a. 不同領域的大師模型
前人已經訓練好了很多模型,可以把他們美妙的與當前任務結合。


在風格轉換任務中,使用了內容損失函數(Content Loss)以及風格損失函數(Style Loss)。最小化兩損失函數的調和平均後能得到風格化的圖。
CLIPstyler的任務一樣是風格轉換,為了保留原始圖片的結構,他們採用了內容損失函數。
而在StyleCLIP中,希望得到的新影像,在感知上還被視為同一個人、但是其他特徵被變換(如:髮型、表情、年紀、口紅),為此他們套用了已存在的ArcFace,這個模型能夠量測不同人臉照片的相似程度(identity loss)。
如果是要改變人物的話,不要使用 identity loss
例如把人臉都變成川普的樣子,那就不套 identity loss
3.b. 不同架構的CLIP
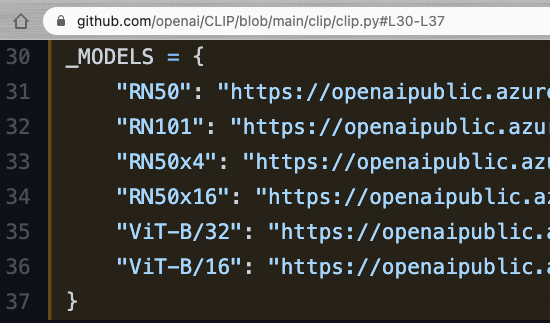
OpenAI在訓練CLIP時有很多實驗,而且他們有釋出不同骨架的模型
在Pixray中,他們使用了CLIP的多個模型來同時計算損失函數。
Pixray 的作者是一個知名的 AI 藝術家 Tom White
他在課程 MIT 6.S192: Deep Learning for Art, Aesthetics, and Creativity 分享的 “Neural Abstractions” 也是做類似的事情,區別在於
Pixray 使用同時使用多個不同骨架的CLIP模型來計算對於文本的相似度
Neural Abstractions 分享的 Perception Engines 同時使用訓練在 ImageNet上的inceptionv3, resnet50, vgg16 and vgg19 來計算對 ImageNet上某個類別的響應程度
4. CLIP空間中的相對位置
白天比晚上熱、餐廳比小吃貴、冬天比夏天冷、馬達加斯加在非洲的東南方
我們可以透過對比的方式來一次帶出兩個物件的相對關係
而且相對關係也是在做指引時一個較為有效的概念
原本的任務是可能是:要到紐約
而實際上比較好的任務描述如下:
- 要從舊金山到紐約
(應該是往東方走) - 要從墨西哥到紐約
(應該是往東北方走)
如果你不知道當前所在位置的話,會不知道該從何走起
以下兩個方法都是要預先註冊當前位置,而後透過相對位置的方式能更好的引導演算法
4.a. StyleCLIP Global Direction
StyleCLIP 的 Global Direction 透過了一個聰明的手法讓他們的演算法能如上方的影片做到實時的任意內容轉換
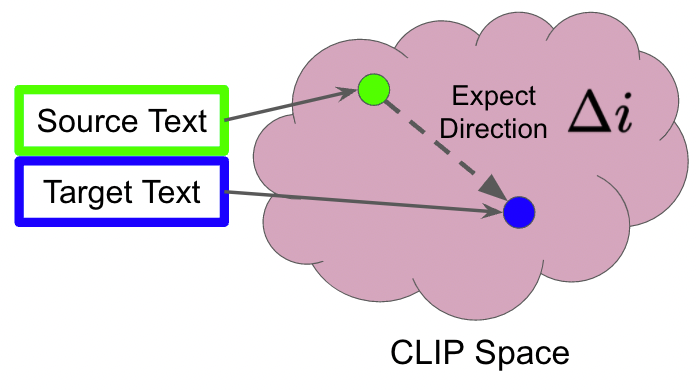
在做該演算法時要有三個輸入(原始影像, 原始影像描述, 目標描述),透過計算(原始影像描述, 目標描述)在CLIP空間中的相對位置(Δi)

而要讓演算法能達到實時,他們的做法是預先註冊StyleGAN中的Latent空間的每個維度(channel)在CLIP空間中的響應方向
最後反推StyleGAN的空間中的方向為以下式子,其中調高閥值β在他們的演算法底下能防止響應其他相關特徵(如伴隨白髮的特征通常為老人的特征,調高閥值β能避免之)
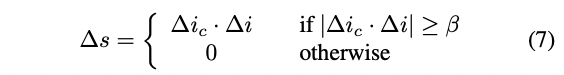

4.b. StyleGAN-NADA directional loss
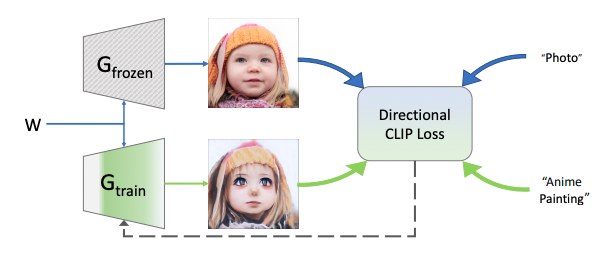
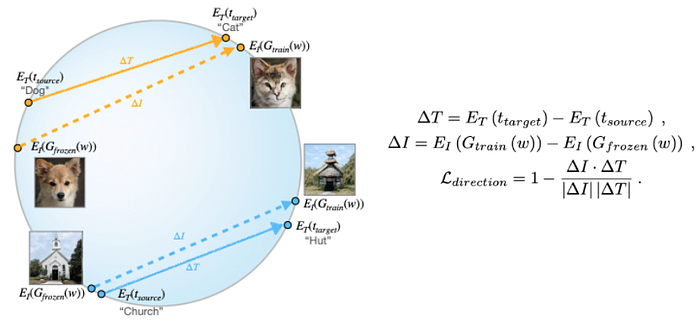
上一小節中StyleCLIP是採用預先註冊(StyleGAN, CLIP)兩個領域的空間關係,並採用後處理的方式去運用向量間的關係
而在StyleGAN-NADA中則直接顯性的將其寫成損失函數,並用這損失函數去更新神經網路的權重
目標是希望下方兩向量的餘弦相似度要越接近 1 越好
- 原文本、目標文字在CLIP做向量相減(ΔT)
- 原模型生成的影像、訓練後模型生成的影像在CLIP做向量相減(ΔI)
5. 資料增量
一般在訓練影像模型時就會套用一些資料增量了,如對影像做放大、縮小、旋轉、平移、擷取、增加雜訊等等
能做這些的原因是因為照片在經過這些轉換後其實還是保留了原本的屬性
5.a. 簡易的增量
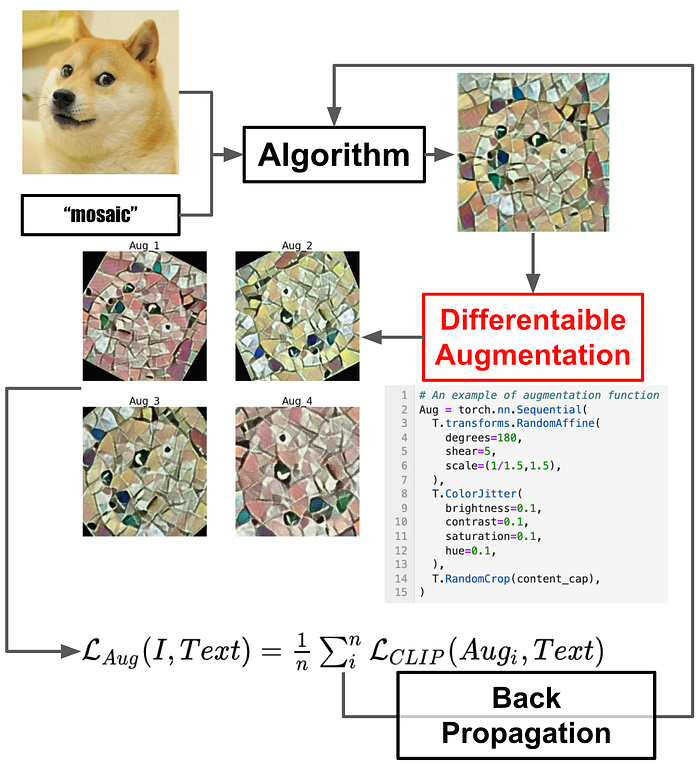
第一個採用CLIP的影像生成專案BigSleep就已經開始使用資料增量
而後續的CLIP影像操弄演算法中很多都有資料增量的蹤跡,我們預期得到的影像應要在經過擾動後還跟輸入的文本相似度很高
最簡易的資料增量如上圖所示,將生成後的圖片經過一些可微分的擾動後得到多張新圖片,再用這些新圖片計算損失函數


而在Text2Mesh中的做法是將3D物件在不同視角投影後的到很多2D照片、又將這些照片做資料增量
5.b. 有必要資料增量嗎?

雖然CLIP模型很棒,能量測照片與文字的相似程度,但是它太容易被惡意攻擊混淆了
- 在FuseDream中的Adv. Example on CLIP
透過攻擊演算法FGSM對像素做擾動,在CLIP下的相似程度會被有效提升(0.195➔0.259),但是對增量版的相似程度幾乎是沒什麼顯著提升 - 在FuseDream中的Adv. Example on AugCLIP
對增量版損失函數套用同樣演算法,有無增量版的CLIP相似度皆是幾乎是沒什麼顯著提升
FGSM是個攻擊的演算法,他對照片加上一些微小的擾動值,肉眼上很難觀測到與原照片的差異
若想了解FGSM推薦觀看李宏毅老師的【機器學習2021】來自人類的惡意攻擊 (Adversarial Attack) (上) — 基本概念
在CLIPDraw、FuseDream在不使用資料增量時的結果皆很差
而在StyleCLIP則不需要使用資料增量也能得到很好得結果
我個人的建議是如果沒有做資料增量沒辦法得到好結果的話,可以嘗試看看資料增量


5.c. 在 Latent 空間上增量

前方介紹了一般的影像增量方式,而FuseDream的演算法實現了在Latent Space下的增量
他們的兩個演算法中的第一個演算法大致如下
- 從BigGAN的Latent空間中採樣 N 點
- 用BigGAN生成這些影像
- 計算這些影像在CLIP底下的分數
- 僅保留分數前 K 高者 (K << N)
- 將這些 Latent 的加權平均當作BigGAN的輸入,最後去依損失函數做梯度下降
6. 個人在風格轉換模型中的實驗結果


google團隊在2017提出的任意風格轉換模型有能力去實時的將任何圖片賦予風格。
他們使用了兩個模型,風格預測模型 P 會將風格圖片編碼成 →S,而轉換模型 T 會將內容圖片 c 以及→S轉換成風格化圖片。

在我的實驗中,要不使用風格影像找到一個最好的→S使得損失函數最低
其中有三組實驗
- 不做資料增量
- 一般資料增量
- 多張圖片 且 資料增量 再計算損失函數
使用一張GTX 1080 Ti、演算法在處理一張384 x 384的影像大概需要1分鐘左右
結果如下
不做資料增量版本






一般資料增量版本






多張圖片 且 資料增量 再計算損失函數版本



在實驗的過程中發現在 不使用 內容損失函數 時,圖片本身的資訊幾乎完全消失,所以新增了使用內容損失函數的版本
不使用內容損失函數






使用內容損失函數






個人方法小結
以結果而言,第二個版本 資料增量 是我比較喜歡、且比較好控制的
個人也有嘗試直接訓練一個模型,直接映射CLIP編碼至風格編碼→S,不過效果非常差
而在預訓練模型上,我使用的是只服務紋理的風格轉換的模型,如果要達成其他任務是沒辦法的
結尾



Images by author, powered by pixray with text prompts : (left) japan bookstore | (mid) city in anime with sunshine | (right) 3d battleship